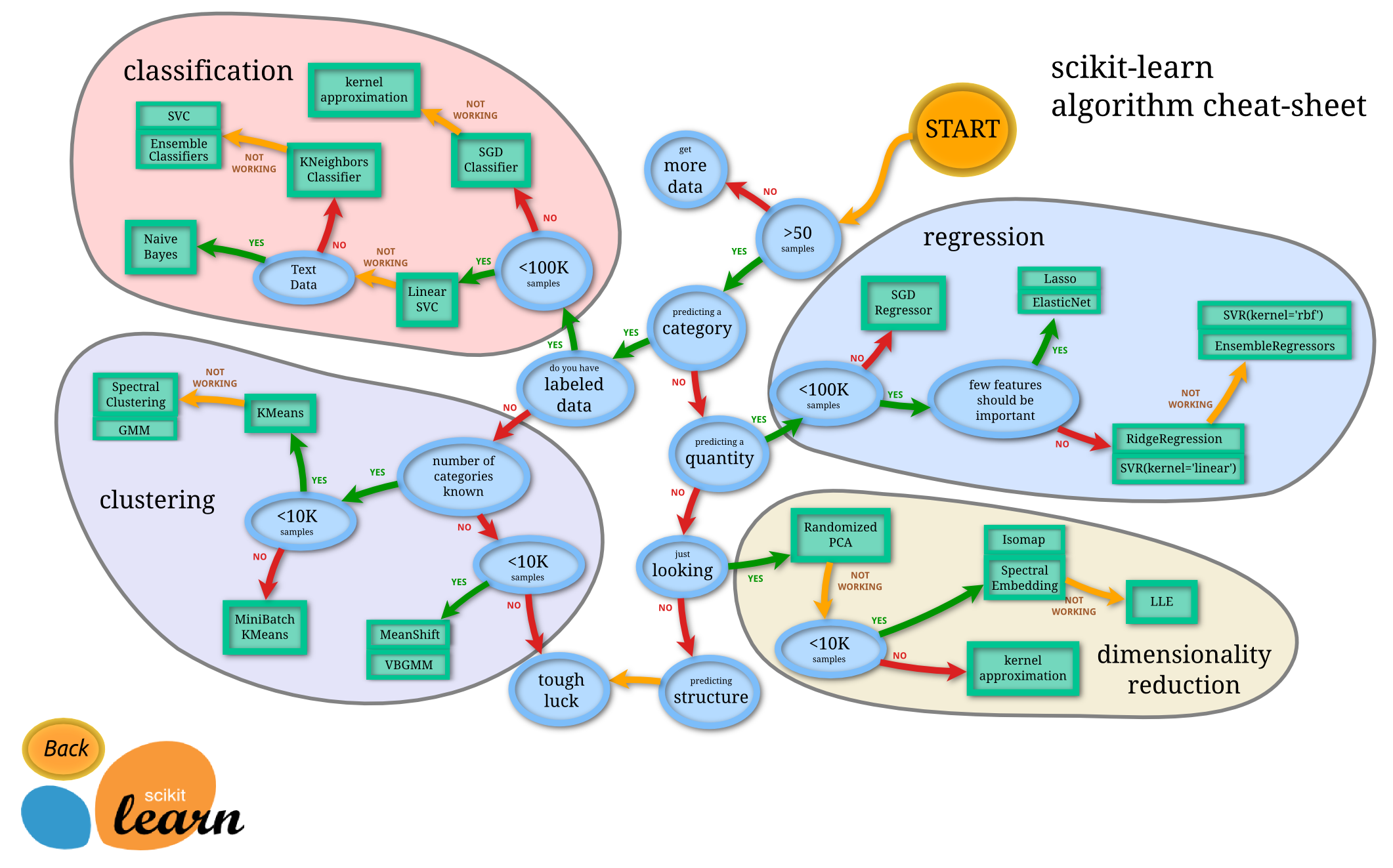
This is my Machine Learning Workflow. It delineates the processes from data cleaning to model ensembling. This document will be updated over time.
Machine Learning Workflow
1) Data Cleaning, EDA, Data Visualization
- Before any data analysis can take place the data must be thoroughly cleaned
- Are all the columns of the correct data type (e.g. are numerical cells of type numeric)?
- Are cells misplaced/shifted in a column? (e.g. numbers accidently in a True/False column)
- Outliers?
- Are there missing cells? Are they blank or
NA? Are they MAR, MNAR, or MCAR?- What will you do with missing cells? Impute? Drop?
- If you impute, how will you impute? Mean imputation? Impute by random duplication? Linear imputation? KNN?
- Once the data is cleaned, perform some preliminary EDA:
- What is the data types of each column?
- what are the mean, median, SD, etc. for continuous numerical data
- how many categories make up categorical variables? (
np.unique()might help) - What is the distribution of continuous variables?
- What are the counts for categories in categorical variables
- Are there meaningful correlations between variables?
2) Feature Engineering
“Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.”
— Dr. Jason Brownlee
- Dervied vs. Raw Features:
- Raw Features are pulled directly from the dataset. Example) A feature called “Boroughs of NY” might contain Manhattan, Queens, Bronx, Staten Island, and Brooklyn
- Derived features are computed from existing features. Example) “Shipping Time” can be determined by subtracting the “Shipment Date” from the “Delivery Date”
- Types of Derived Feature Engineering (numerical continuous):
- Binarization (
scikit-learnbinarizer) - Rounding (
np.round()) - Interactions (
from sklearn.preprocessing import PolynomialFeatures, perform mathematic operations between features) - Binning/Quantization (changes continuous numeric features into discrete (categories))
- Fixed Width (e.g. Ages: 0-9, 10-19, etc.)
- Adaptive (e.g. q-Quantile (bin depending on 2-, 4-, 10-, quantiles))
- Statistical Transformations
- Monotonic Data Transformations
- Box-Cox (caution: numeric values to be transformed must be positive)
- Log Tranformation
- Monotonic Data Transformations
- Binarization (
- Types of Derived Feature Engineering (discrete nominal/ordinal):
- Nominal:
- Transform nominal (try
from sklearn.preprocessing import LabelEncoder) - One-hot enconding scheme (binarization of transfomed categorical variables, creates dummy variables)
- Active state is typically indicated by “1” in of those dumy variables.
- try
to_dummies(…)function frompandas
- Dummy Coding Scheme
- drops the last dummy variable (therefore a row full of 0’s indicates that the dropped dummy variable is active)
- Effect Coding Scheme
- similiar to Dummy Coding Scheme except the row(s) of all 0’s are replaced by -1’s
- Bin Counting Scheme
- Best used when the distinct categories of a feature a large (e.g. the “No-Fly List” is essentially a Bin Counting Scheme for people who cannot participate in air travel.)
- Feature Hashtag Scheme
- Good for large scale categorical features
- Allows you to predefine a feature vetor size which can reduce the amount of dummy variables used to identify a feature
- Transform nominal (try
- Ordinal:
- Transform ordinal (
map()is useful for this) - Encoding Schemes see nominal
- Transform ordinal (
- Nominal:
3) Model Building